Deep Learning
Deep learning is the study of artificial neural networks and related machine learning algorithm that contain more than one hidden layer
Computer Vision
Computer vision is an interdisciplinary field that deals with how computers can be made for gaining high-level understanding from digital images or videos.
Machine Learning
Machine learning explores the study and construction of algorithms that can learn from and make predictions on data, overcoming following strictly static program instructions.
Dr. A. Vezhnevets (Google DeepMind)
- Wednesday, May 31, 2017
- 15.00-16.00, Room C1.110
- Science Park, UvA
Title: FeUdal Networks for Hierarchical Reinforcement learning
Abstract: Arrival of deep learning has allowed for a significant progress in reinforcement learning (RL). Nevertheless, learning complex behaviours in environments with sparse reward signals, like infamous ATARI Montezuma's revenge, remain a challenge. It is harder still if an environment is partially observable and requires memory. This talk will start with a little introduction into deep RL. The second part will focus on FeUdal Networks (FuNs): a novel network architecture for hierarchical RL. FuN learns to decompose its behaviour into meaningful primitives and then reuse them to more efficiently acquire new, complex behaviours. This allows it to reason on different temporal resolutions and thereby improve long-term credit assignment and memory. FuN dramatically outperform a strong baseline agent on tasks with sparse reward or requiring memorisation. I will demonstrate its performance on a range of tasks from the ATARI suite and also from a 3D DeepMind Lab environment.
Bio: Alexander (Sasha) Vezhnevets is a Senior Research Scientist at Google DeepMind, working on hierarchical reinforcement learning. He got his PhD from ETH Zurich Machine Learning Lab, where he worked on weakly supervised semantic segmentation. He did a post doc at the University of Edinburgh working on object detection and recognition.



Dr. J. Sivic (INRIA Paris)
- Friday, Mar 31, 2017
- 15.00-16.00, Room C0.05
- Science Park, UvA
Title: Joint Discovery of Object States and Manipulation Actions
Abstract: Many human activities involve object manipulations aiming to modify the object state. Examples of common state changes include full/empty bottle, open/closed door, and attached/detached car wheel. In this work, we seek to automatically discover the states of objects and the associated manipulation actions. Given a set of videos for a particular task, we propose a joint model that learns to identify object states and to localize state-modifying actions. Our model is formulated as a discriminative clustering cost with constraints. We assume a consistent temporal order for the changes in object states and manipulation actions, and introduce new optimization techniques to learn model parameters without additional supervision. We demonstrate successful discovery of seven manipulation actions and corresponding object states on a new dataset of videos depicting real-life object manipulations. We show that our joint formulation results in an improvement of object state discovery by action recognition and vice versa.
Bio: I am a senior researcher (roughly equivalent to associate professor with tenure) at INRIA working in the Willow project at the Department of Computer Science at Ecole Normale Supérieure. I completed my PhD at the University of Oxford working with Professor Andrew Zisserman and received my habilitation degree at Ecole Normale Supérieure in Paris. Before coming to France I spent six months as a post-doc in the Computer Science and Artificial Intelligence Lab (CSAIL) at MIT working with Prof. William Freeman. My research is in computer vision - a branch of computer science and engineering that aims to extract information from images. I am particularly interested in developing learnable image representations for automatic visual search and recognition applied to large image and video collections. I lead the ERC project LEAP .
Dr. M. Bethge (MPI Tübingen)
- Friday, Mar 10, 2017
- 15.00-16.00, Room C0.110
- Science Park, UvA
Title: Modeling human perception with deep neural networks
Abstract: Understanding the brain means to understand the neural basis of biological fitness. Recently, the rise of deep neural networks has substantially improved computer vision towards achieving human performance on ecologically relevant tasks such as object recognition, semantic image segmentation, and one-shot learning. In this talk I will present some results of my group that use the advances in computer vision for developing models of visual perception in humans. In particular, I will talk about the dual nature of texture and object perception, eye movement prediction, and noise robustness.
Bio: I did my undergraduate studies in physics and started working in computational neuroscience when I joined the MPI for dynamics and self-organization for my diploma project. Since then my research aims at understanding perceptual inference and self-organized collective information processing in distributed systems---two puzzling phenomena that contribute much to our fascination about living systems. General principles are important but at the same time these principles need to be grounded in reality. Therefore, a large part of my research focuses on the mammalian visual system working closely together with experimentalists ( Andreas Tolias , Thomas Euler , Felix Wichmann ). I also work on neural coding in other sensory systems (collaborations with Cornelius Schwarz). More generally, I want my work to have a positive impact on many people's lives. I enjoy collaboration and learning new things every day. Besides working together with a great team of people to develop new ideas and bring them to life I have a few other jobs that I am committed to: Chair of the Bernstein Center for Computational Neuroscience Tuebingen, Deputy chair of the Bernstein Network Computational Neuroscience, Board member of the Werner-Reichardt Centre for Integrative Neuroscience, Program coordinator of the Graduate School of Neural Information Processing, Associate Editor of PLOS Computational Biology.
Dr. J. Yosinski (Uber, Geometric Intelligence)
- Friday, Dec 2, 2016
- 13.00-14.00, Room C1.110
- Science Park, UvA
Title: A deeper understanding of large neural nets
Abstract: Deep neural networks have recently been making a bit of a splash, enabling machines to learn to solve problems that had previously been easy for humans but hard for machines, like playing Atari games or identifying lions or jaguars in photos. But how do these neural nets actually work? What do they learn? This turns out to be a surprisingly tricky question to answer — surprising because we built the networks, but tricky because they are so large and have many millions of connections that effect complex and hard to interpret computation. Trickiness notwithstanding, in this talk we’ll see what we can learn about neural nets by looking at a few examples of networks in action and experiments designed to elucidate network behavior. The combined experiments yield a better understanding of network behavior and capabilities and promise to bolster our ability to apply neural nets as components in real world computer vision systems.
Bio: Jason Yosinski is a researcher at Geometric Intelligence, where he uses neural networks and machine learning to build better AI. He was previously a PhD student and NASA Space Technology Research Fellow working at the Cornell Creative Machines Lab, the University of Montreal, the Caltech Jet Propulsion Laboratory, and Google DeepMind. His work on AI has been featured on NPR, Fast Company, Wired, the Economist, TEDx, and BBC.
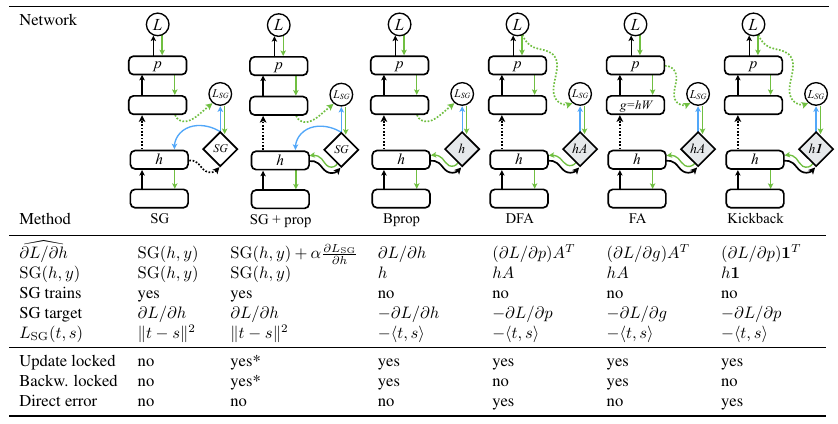
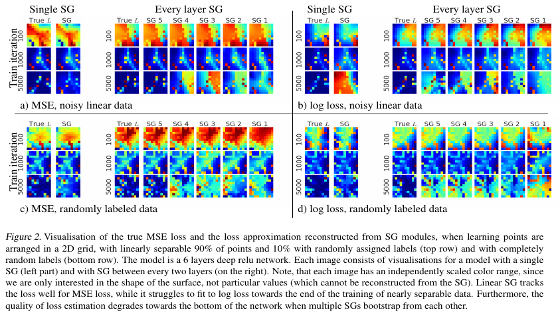
Dr. M. Jaderberg (Google DeepMind)
- Friday, Oct 28, 2016
- 11.30-13.00, Room C0.110
- Science Park, UvA
Title: Temporal Credit Assignment for Training Recurrent Neural Networks
Abstract: The problem of temporal credit assignment is at the heart of training temporal models -- how the processing or actions performed in the past affects the future, and how we can train this processing to optimise future performance. This talk will focus on two distinct scenarios. First the reinforcement learning scenario, where we consider an agent which is a recurrent neural network which takes actions in its environment. I will show our state-of-the-art approach to deep reinforcement learning, and some of the latest methods which deal with enhancing temporal credit assignment, presenting results on new 3D environments. I will then look at how temporal credit assignment is performed more generically during the training of recurrent neural networks, and how this can be improved by the introduction of Synthetic Gradients -- predicted gradients from future processing by local models learnt online.
Bio: The problem of temporal credit assignment is at the heart of training temporal models -- how the processing or actions performed in the past affects the future, and how we can train this processing to optimise future performance. This talk will focus on two distinct scenarios. First the reinforcement learning scenario, where we consider an agent which is a recurrent neural network which takes actions in its environment. I will show our state-of-the-art approach to deep reinforcement learning, and some of the latest methods which deal with enhancing temporal credit assignment, presenting results on new 3D environments. I will then look at how temporal credit assignment is performed more generically during the training of recurrent neural networks, and how this can be improved by the introduction of Synthetic Gradients -- predicted gradients from future processing by local models learnt online.
Prof. I. Kokkinos (UCL, Facebook)
- Friday, Sep 29, 2016
- 13.00-14.00, Room C3.136
- Science Park, UvA
Title: Deeplab to UberNet: from task-specific to task-agnostic deep learning in computer vision
Abstract: Over the last few years Convolutional Neural Networks (CNNs) have been shown to deliver excellent results in a broad range of low- and high-level vision tasks, spanning effectively the whole spectrum of computer vision problems.
In this talk we will present recent research progress along two complementary directions.
In the first part we will present research efforts on integrating established computer vision ideas with CNNs, thereby allowing us to incorporate task-specific domain knowledge in CNNs. We will present CNN-based adaptations of structured prediction techniques that use discrete (DenseCRF - Deeplab) and continuous energy-based formulations (Deep Gaussian CRF), and will also present methods to incorporate ideas from multi-scale processing, Multiple-Instance Learning and Spectral Clustering into CNNs.
In the second part of the talk we will turn to designing a generic architecture that can tackle a multitude of tasks jointly, aiming at designing a `swiss knife’ for vision. We call this network an ‘UberNet’ to underline its overarching nature. We will introduce techniques that allow us to train an UberNet while using datasets with diverse annotations, while also handling the memory limitations of current hardware. The proposed architecture is able to jointly address (a) boundary detection (b) saliency detection (c) normal estimation (d) semantic segmentation (e) human part segmentation (f) human boundary detection (g) region proposal generation and object detection in 0.7 seconds per frame, with a level of performance that is comparable to the current state-of-the-art on these tasks.
Bio: Iasonas Kokkinos obtained the Diploma of Engineering in 2001 and the Ph.D. Degree in 2006 from the School of Electrical and Computer Engineering of the National Technical University of Athens in Greece, and the Habilitation Degree in 2013 from Université Paris-Est. In 2006 he joined the University of California at Los Angeles as a postdoctoral scholar, and in 2008 joined as faculty the Department of Applied Mathematics of Ecole Centrale Paris (CentraleSupelec). He is currently an associate professor in the Center for Visual Computing of CentraleSupelec and is also affiliated with INRIA-Saclay in Paris. His research activity is currently focused on deep learning and efficient algorithms for object detection. He has been awarded a young researcher grant by the French National Research Agency, serves regularly as a reviewer for all major computer vision conferences and journals, and is an associate editor for the Image and Vision Computing and the Computer Vision and Image Understanding journals.